Khi đọc về thuật toán
Nearest Neighbor, ai nói thuật toán đó là vớ vẩn thì bước ra đây! Mấy người đúng rồi đấy =)) Đúng là NN rất vớ vẩn, với một người không giỏi toán như mình, khi nhìn nhận NN qua xác xuất thống kê đã thấy không ổn rồi. Chẳng ai lại đoán nhãn của 1 đối tượng dựa vào duy nhất 1 đối tượng gần nó nhất. Việc này cũng như tính toán tỉ lệ úp ngửa khi thảy đồng xu, chả ai lại thảy 1 lần duy nhất là đưa ra tỉ lệ cả. Và vì lí do cùi mía này, người ta có 1 thuật toán khác gọi là: K-Nearest Neighbor (KNN) để loại bỏ đi cái sự vớ vẩn của NN. Ý tưởng của KNN thực sự rất đơn giản, thay vì dự đoán nhãn của 1 đối tượng dựa vào 1 đối tượng gần nó nhất, người ta sẽ dựa vào K đối tượng gần nó nhất. Điều này ít nhất là giúp mình thấy có chút ngon lành theo mặt xác suất thống kê ( mặc dù mình dốt toán).
K-Nearest Neighbor Classifier là phương pháp mà bạn dự đoán nhãn của 1 đối tượng dựa vào nhãn của K đối tượng gần nó nhất.
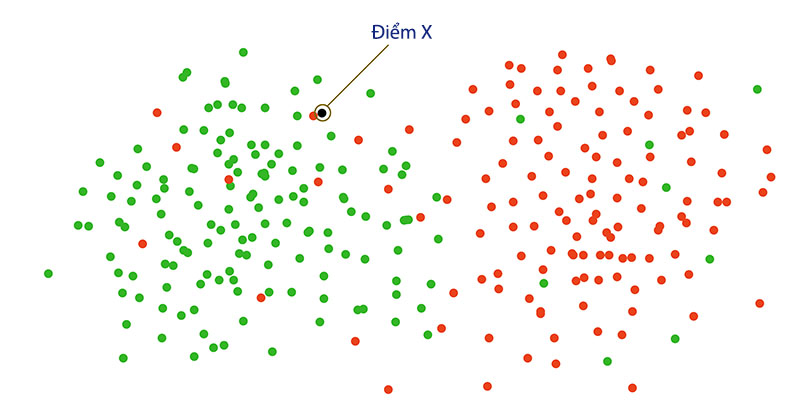
Từ định nghĩa trên, có thể dễ dàng nhận thấy: với K = 1 thì KNN thực chất là NN. Với hình dưới đây, nếu như ta dùng NN để dự đoán X, thì chắc chắn sai. Nếu đúng ra, điểm X nên nhận giá trị màu xanh, nhưng vì nó gần với điểm đỏ nên theo NN nó là màu đỏ.
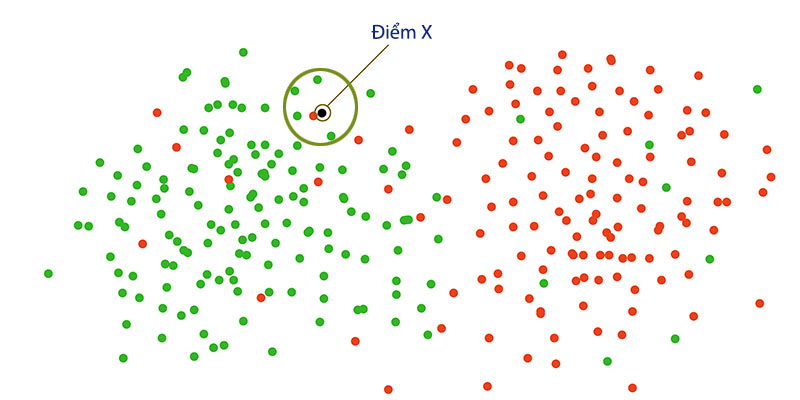
Những điểm đỏ nằm lẫn trong các điểm xanh, người ta gọi nó là dữ liệu nhiễu. Và hầu như các bộ dataset đều có dữ liệu nhiễu, đó là lí do mà NN đạt hiệu quả thấp. Nhưng nếu ta dùng KNN cho trường hợp này với K = 5, thì kết quả sẽ có 4 đối tượng màu xanh và 1 đối tượng màu đỏ. Theo số đông, thì nhãn của X sẽ là màu xanh.
Thấy thế nào, thuật toán này ngon lành nhỉ? Nhưng không đâu bạn à, vấn đề đặt ra ở đây là: K bao nhiêu là tốt nhất. Nếu muốn tối ưu, thì ta còn phải chọn độ đo nào (Mahattan hay Euclidean). Và những tham số cần phải chọn như này, người ta gọi là Hyperparameter (tiếng việt là siêu tham số). Và để chọn siêu tham số như nào, thì chỉ còn có cách là thử nghiệm. Các phương pháp thử nghiệm thì có rất nhiều, và bạn có thể đọc phương pháp
Cross Validation để có thể thử code KNN và chạy thử.







0 Nhận xét