

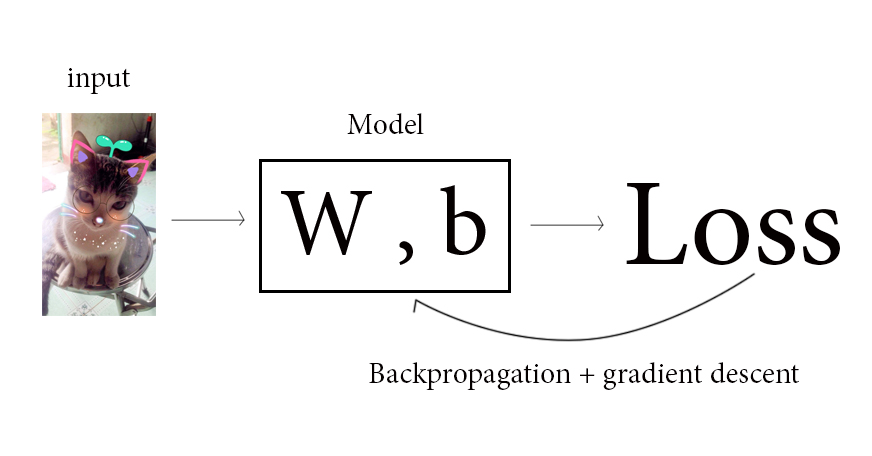
Tiếp đến, quá trình backpropagation bắt đầu. Khởi động quá trình tính đạo hàm riêng điên loạn cho toàn bộ W và b trong model. Sau khi tính được đạo hàm riêng, gradient descent sẽ được áp vào để cập nhật các W và b. Và vòng lặp thứ nhất kết thúc.
Vòng lặp thứ 2 bắt đầu! Bức ảnh lại được đưa vào, model lại tiếp tục tính toán theo score function. Nhưng vì ở vòng lặp thứ nhất, các W và b đã được cập nhật theo gradient descent, do đó ở lần lặp này, loss function được tính ra sẽ thấp hơn loss function ở lần lặp trước. Điều này đánh dấu cho một sự kiện quan trọng của học máy: qua quá trình lặp, kết quả dự đoán đã chính xác hơn. Tiếp đến sẽ lại là quá trình backpropagation và cập nhật model. Quá trình này lặp cho đến khi nào loss đủ nhỏ mà người dùng ưng ý thì sẽ dừng hoặc sẽ dừng sau 1 số hữu hạn vòng lặp đã được lập trình.
Và đó, tất cả quá trình lặp forward và backpropagation đó, là quá trình máy học. Quá đơn giản đúng không nào!





0 Nhận xét