

def predict(self, X):Lưu ý là, để chạy được hàm Counter, các bạn phải thêm thư viện vào bằng dòng code sau đây:
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in xrange(num_test):
print i
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
k=7
min_indexes = np.argpartition(distances, k)[:k] # vị trí k ảnh gần nhất
yget = self.ytr[min_indexes] # yget chứa nhãn của k ảnh gần nhất
c = Counter(yget).most_common(1) # lấy ra nhãn xuất hiện nhiều nhất trong yget
Ypred[i] = c[0][0] # gán giá trị nhãn đó cho kết quả
return Ypred
from collections import CounterSau khi để máy chạy một hồi, kết quả bạn thu được sẽ là: 37,65%. What the fuck????? Có gì đó sai sai ở đây, KNN dự đoán thua NN??? Đó là cảm giác của mình sau khi chạy xong code ở trên. Sau một hồi xem xét, thì hóa ra lỗi là ở đoạn code sau:
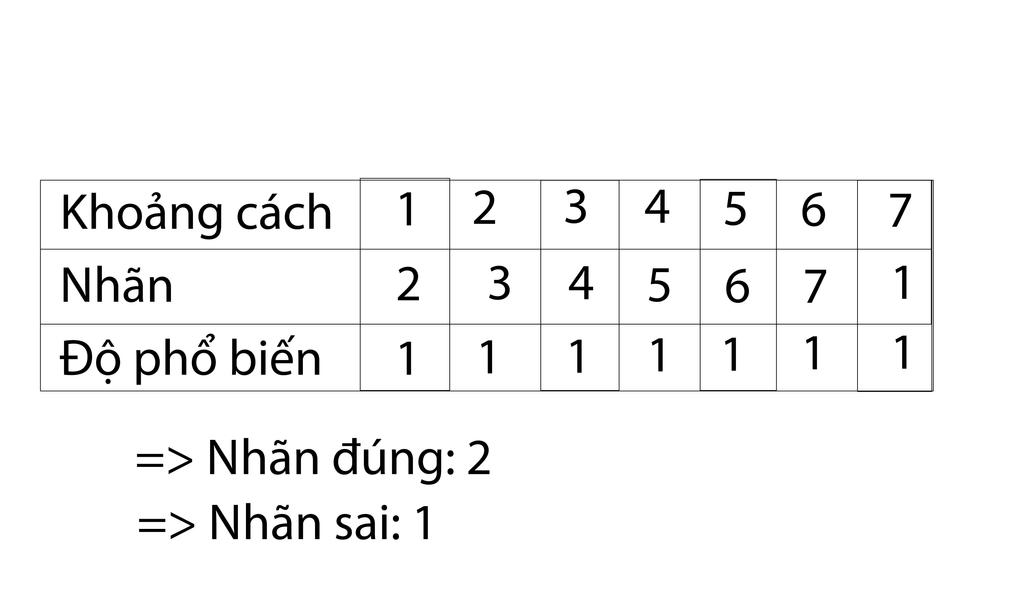
c = Counter(yget).most_common(1)Oái ăm là vầy, nếu như tất cả các nhãn trong yget xuất hiện phổ biến ngang nhau, thì đoạn code trên sẽ trả về nhãn có giá trị nhỏ nhất.
Ypred[i] = c[0][0]
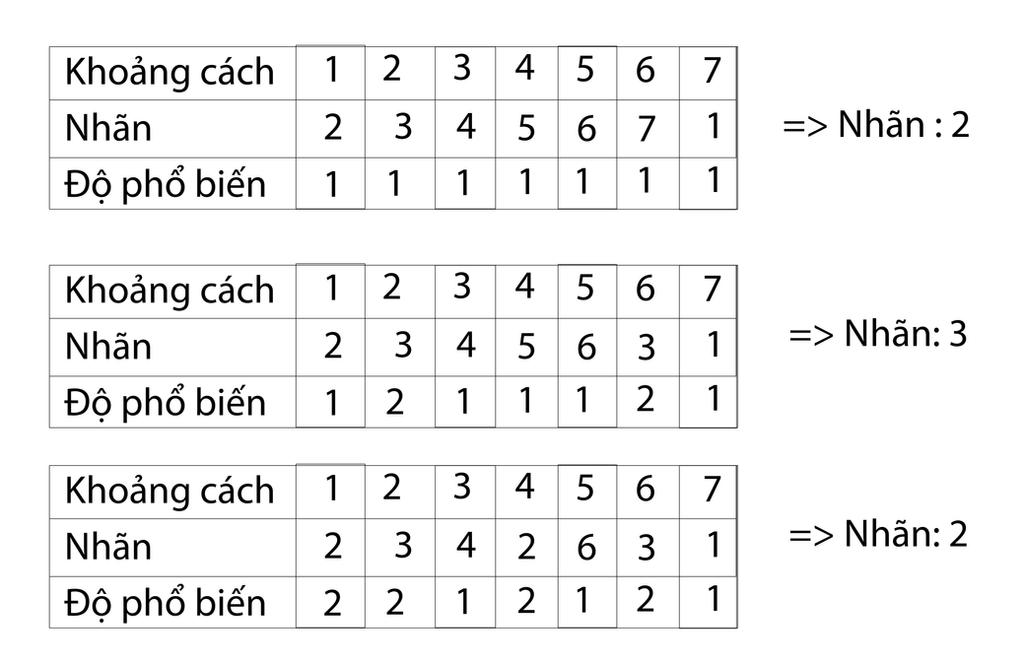
def predict(self, X,k):Nhìn thì có vẻ rối, nhưng cơ bản đoạn code trên giải quyết những trường hợp sau:
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in xrange(num_test):
print i
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_indexes = np.argpartition(distances, k)[:k]
yget = self.ytr[min_indexes]
c = Counter(yget).most_common(k)
result = c[0][0]
if c[0][1]==1:
k = 1
min_indexes = np.argpartition(distances, k)[:k]
yget = self.ytr[min_indexes]
c = Counter(yget).most_common(k)
result = c[0][0]
else:
i = 0
while i<len(c)-1 and c[i][1]==c[i+1][1]:
i = i+1
if i!=0:
result = c[0][0]
k2 = 1
ind2 = np.argpartition(distances, k2)[:k2]
yget2 = self.ytr[ind2]
c2 = Counter(yget2).most_common(1)
for y in range(0,i):
if c[i][0]==c2[0][0]:
result = c[i][0]
Ypred[i] = result
return Ypred




0 Nhận xét